字符集、编码的前世今生
当前位置:点晴教程→知识管理交流
→『 技术文档交流 』
1 ASCII的诞生20世纪60年代的美国,计算机发展到集成电路阶段,体积不断缩小,功能不断增强,应用软件开始出现。但当时每个厂家都按自己的喜好来编码,有的用6位表示一个字符,有的用7位表示一个字符,不同厂家之间有不同标准,软件不能跨设备运行,两个厂家生产出来的计算机无法交流。当时,编码方式超过60种,仅IBM一家公司在自家不同的设备上就有9种不同的编码。这时IBM里有位程序员意识到了这个问题,他认为所有厂家的编码应该统一起来,并且从1960年开始干这个活,一年后他向ANSI(美国国家标准协会)提出统一计算机编码的建议,ANSI觉得这个想法不错,于是把各大厂商召集起来开会,利益纷争的座谈会一直开到1967年,ANSI实在受不了了,说算了你们别争了,26个英文字母加10个数字加常用的书写符号再加流行的打印控制凑齐128个,用7位存储,前面32个用于控制,后面的用于显示,128一二发,大吉大利,就这样定了吧。 次年,美国总统林登·约翰逊下达红头文件,所有的计算机厂家必须遵循ANSI的标准。于是,大名鼎鼎的ASCII诞生。促成ASCII编码的这位IBM员工的名字是:Bob Bemer(鲍勃·贝莫)
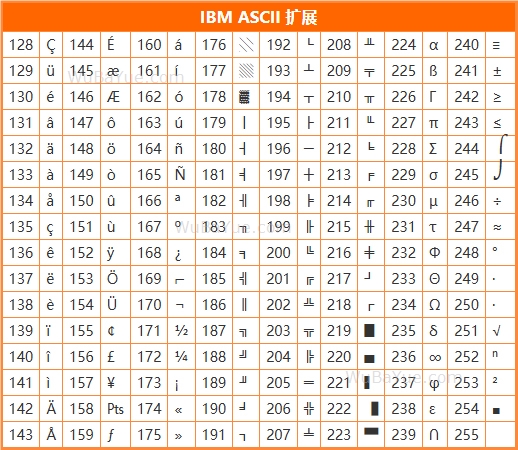
2 ASCII的自由扩展以后的若干年,ASCII在美国不温不火,各厂家拿着红头文件照章办事,直到1981年,一件石破天惊的事情让世人重新重视和开始讨论ASCII,这就是IBM个人电脑(PC)的诞生。PC完全颠覆了人们对计算机的印象,它成本低廉,体积小巧,很快就开始在全球蔓延。PC到了英国,英国人发现他们的英镑符号£在万能的PC里显示不出来;PC到了希腊,希腊人发现让他们引以为傲的希腊字母居然在PC里一个也敲不进去。IBM根据市场反馈,很快就决定把ANSI的7位ASCII标准扩展成8位,这样就多出了一倍的字符。
当时生产PC的可不止IBM一家,大多数人知道现在的iPhone、iPad称霸全球,但很多人不知道早在1977年乔帮主的Apple II就在江湖上叱诧风云。同样,乔帮主也毫不犹豫的把ANSI的7位扩展成了8位,还特意把240这个值设计成苹果的标识。俗话说性格决定命运,也许乔帮主在扩展ASCII中画下被啃掉一口苹果的那天,就决定了30年后创造出的万亿美元市值公司。
3 GB2312
信息革命是继蒸汽革命、电气革命之后人类历史上第三次科技革命,虽然信息革命发源于美国,但中国人民很早就意识到了信息革命的重要性。在IBM电脑兴起的时候,我们召开完了十一界三中全会,聪明勤劳的中国人民敏锐的意识到汉字也需要信息化,但美帝规定的ASCII只有7位,即便扩展为8位,也容纳不下博大精深的汉字,于是我们毫不犹豫的把一个字节扩展成两个字节,考虑到兼容ASCII,将前面32个控制字符排除掉,高低位字节组合起来就有94X94=8836个,掐指一算,常用汉字够了,顺带还可以将ASCII用两个字节再重编码一遍,于是便有了今天的全角半角字符之分。 1980年,中国国家标准总局制定了《信息交换用汉字编码字符集》,1981年5月1日开始正式实施,标准号是:GB2312-80,选入了6763个汉字,分为两级,一级字库中有3755个,是常用汉字,二级字库中有3008个,是次常用汉字;还选入了682个非汉字图型字符,包含数字、一般符号、拉丁字母、日本假名、希腊字母、俄文字母、拼音符号、注音字母等。整个字符集分成94个区,每区有94个位。每个区位上只有一个字符,因此可用所在的区和位来对汉字进行编码,称为区位码。1996年我们学校机房所有的486电脑上统一安装的就是拼音、五笔和从来没人会用的区位码。 4 BIG5因为特殊历史背景原因,GB2312在设计时并未考虑支持繁体中文,当时作为亚洲四小龙之一的台湾省,经济腾飞,计算机快速普及,但同样,台湾厂商各自采用不同的中文编码方式,数据交互困难,台湾人民的屏幕上乱码满天飞。于是在1983-1984年间,宏基(Acer)、神通(Mitac)、佳佳(KaoHSIN)、零一(Zero One)、大众(FIC)五家商业公司共同制定了统一的繁体中文编码标准,也许他们觉得自己应该是台湾最大的五家公司,所以将这个编码称之为大五码(BIG5)。BIG5采用双字节编码,收录了常用与次常用繁体汉字13060个,以及日、俄、希腊字母、标点符号等共计1.9万个字符,但遗憾的是BIG5不支持简体中文,也不兼容GB2312,这样在一个国家的两个地区,使用着相同的语言文字,但计算机中存储着两种完全不同的编码。 5 GBK时间来到九十年代,中国的改革开放在小平同志的带领下初见成效,两岸三地的经济文化交流日益频繁,普通家庭开始拥有个人电脑。同时,远在大洋彼岸的比尔盖茨正带领着微软紧锣密鼓的开发着划时代的操作系统Windows95,他们发现GB2312标准并不支持一些实际使用的汉字,比如常用于人名的“镕”、“喆”、“犇”、“垚”等,于是微软开始在GB2312的基础上进行扩展,除了增加GB2312标准中不支持的简体字,还打包了BIG5中所有繁体字以及日韩语中使用的汉字共计21003个,将其命名为“国标扩展(Guo Biao Kuozhan)”,缩写就是“GBK”。因为GBK并不是国家标准,只是微软作为商业公司基于市场需求推出的编码规范,所以这也为后来中文编码的标准化埋下了隐患。 微软作为一家美国公司,之所以能果断快速的基于GB2312扩展出GBK,完全是借助了另一支强大力量,1993年,国际标准化组织(ISO)和国际电工委员会(IEC)联合发布了ISO/IEC 10646-1,这是旨在统一全球编码的一份国际标准,从西方的拉丁语、希腊语、斯拉夫语,到东方的日语、韩语、汉语,包括GB2312与BIG5中的字符,均在涵盖范围之内。同年,中国国家技术监督局采用了ISO/IEC 10646-1,颁布国标GB13000.1。所以微软只是将GB2312与ISO/IEC 10646-1两大标准进行了融合,它充当了国家标准向国际标准磨合过渡的润滑剂,满足那段特殊历史时期的市场需求,GBK编码也随着Windows95迅速走进了中国的千家万户。 再来看一下使用粤语的香港和澳门地区,他们与台湾一样使用的是繁体字,所以字符编码采用BIG5,但粤语中的一些特殊字符比如“邨”、“埗”、“涌”,在BIG5并未支持,于是香港政府不得不发布香港增补字符集(HKSCS,Hong Kong Supplementary Character Set)。 我们回顾一下当时的中文编码情况,支持简体中文的GB2312,支持繁体中文的BIG5,基于BIG5为粤语打的补丁HKSCS,计划但尚未完成一统天下的ISO/IEC 10646,支持GB2312与BIG5中的字符但两者编码又不兼容的国标GB13000.1,兼容GB2312且支持BIG5中字符但不是国标的GBK,真是一个万码奔腾的时代! 6 Unicode的诞生在漫长的人类发展历史中,有些人总能看穿时间,洞悉未来。比如来自苹果和施乐公司的工程师Mark Davis、Lee Collins和Joe Becker,早在1987年就认为全世界所有文字符号终将融合,需要一份统一的编码,他们于1988年发布了第一个试行标准Unicode 88,又于1991年推出了正式标准Unicode 1.0并成立Unicode联盟。与Unicode有着相同伟大构想的还有另外两家美国事业单位,也是上一章中曾经提到过的国际标准化组织(ISO)和国际电工委员会(IEC),他们计划通过通用字符集(UCS,Universal Character Set)统一全世界的字符编码并为此进行了多年的工作。幸运的是Unicode与ISO/IEC两个项目组都意识到这个世界不需要两种不兼容的字符集,自从他们知道了彼此的存在后便约定将协同工作,编码完全相互兼容,并且以Unicode的名号昭告天下,因为这个名字更容易被记住。稍有遗憾的是说英语的美国人严重低估了这个世界其它语言的复杂性,早期的Unicode团队认为16位支持的65536个字符足够这个世界使用,但其实这个长度还不够存放中国的象形文字,这些都不影响Unicode的伟大,只是在漫长的90年代,Unicode不温不火,隐姓埋名,它在等待逆天改命的一个机会。 1999年,一款名为OICQ的即时通讯软件火遍了中国大江南北,那年我上大一,成宿的跟异性网友在OICQ上聊天,现在的年青人无法理解,是因为他们无法体会从邮寄信件的笔友突然跨越到OICQ聊天的那种代差感;同时,新浪、网易、搜狐三大门户已将传统纸媒打折了腿下一步就该按在地上摩擦了;初代网络游戏《石器时代》已开始改变玩家们对游戏的认知,而帮助陈天桥成为中国首富的《传奇》也正在韩国发布上线。互联网的惊涛骇浪正在席卷全球,所有国家的人们,都迫切的需要一个统一的字符集编码,而Unicode,正是那个不二之选。从1991到1998的七年间,Unicode只迭代了4个版本,而从1998到1999的一年时间,Unicode就迭代了5个版本。 7 Unicode的规则很多人误以为Unicode与GB2312、GBK、甚至UTF-8一样,是一种具体的字符集编码方式。其实Unicode并不是某种字符集编码,而是一个标准化组织,负责制定一系列规则,基于这些规则,Unicode推出了三种具体的编码:UTF-8、UTF-16、UTF-32。 规则1:Unicode字符编码空间为U+0000至U+10FFFF码点是为每个字符分配的唯一数字标识,在Unicode中以U+作为前缀,以16进制表示,比如字母“A”的Unicode码点是U+0041(十进制为65),汉字“中”的码点是U+4E2D(十进制为20013),码点的取值范围叫做编码空间。 细心的你也许留意到了,Unicode编码空间的起始U+0000与结束U+10FFFF,长度并不一样。是的,大多数事物并非天生完美而是靠后天不断完善的,Unicode最早计划使用两个字节16位支持65536个码点,但遇到中国的象形文字后发现这个范围明显太小了,而好基友ISO计划使用四个字节32位支持大约4亿个码点,又明显太大了,于是双方一合计,掐头去尾21位支持一百多万码点,差不多刚刚好,于是编码空间的上限便从U+FFFF(216)扩展到了U+10FFFF(221)。 Unicode编码空间被均分为17份,称为17个平面(Plane),编号0到16,每个平面包含为216即65536个码点,平面又进一步划分为块(Block),不同平面不同块中存储着不同类型的Unicode字符集。 规则2:具有相同含义的字符是同一个字符Unicode规定了字符抽象原则,一个字符可能有多种形状,但只要它们具有相同的含义,就认为是同一个字符,比如同一个汉字,行、楷、隶、草不同字体下的形状各不相同,但Unicode认为它们是同一个汉字,分配唯一的码点。 规则3:使用简单字符组合出复杂字符Unicode还规定了动态组合原则,使用简单的字符组合出复杂的字符,比如瑞典语字符Å,就是由字母A和 ̊ 组合而成。 规则4:兼容以前的字符集编码Unicode诞生于万码崩腾的年代,目标是统一市面上所有的字符集编码,为了这个目标,Unicode联盟在成立之初便制定了一项重要原则:双向兼容所有现有字符集的编码标准。所谓双向兼容,就是当前任何字符集中的任何一个编码都可以转换为Unicode,并且可以再从Unicode转换回原有字符集。因此,在Unicode中就存在一些“冗余”字符,比如拉丁字母“K”与热力学单位“K”(开尔文)看起来完全一样,但为了与之前一些字符集编码的兼容,它们在Unicode中存在两个不同的码点,U+004B为拉丁字母K,名称为“Latin Capital Letter K”,U+212A为热力学单位K,名称为“KELVIN SIGN”。Unicode中的每个码点都有一个全局唯一的大写名称,https://www.unicode.org/Public/UNIDATA/NamesList.txt可以查看所有Unicode字符名称。 8 UTF-8一统江湖Unicode联盟根据自己制定的一系列规则,推出了三种具体的编码方案:UTF-8、UTF-16、UTF-32。其中数字8、16、32称之为码元,表示在计算机中存储Unicode字符的最小单元,比如UTF-8的码元为8位,如果8位存不下一个字符就会扩展至8的整倍数16位,16位再存不下就会扩展至24位,而不允许使用9位或10位。UTF的含义是Unicode转换格式(Unicode Translation Format),它负责将Unicode码点以特定的码元存储在计算机中,所以UTF-8表示使用8位码元存储数据,UTF-16表示使用16位码元存储数据,UTF-32表示使用32位码元存储数据。 Unicode最早推出的是16位双字节的定长编码方案,但这个方案有一个致命缺陷,就是不兼容ASCII,我们知道ASCII是在1968年诞生的,而Unicode的推出时间已到了九十年代,这前后二十多年间,世界上产生了大量基于ASCII的文档和软件,要让它们全部从8位ASCII迁移至16位Unicode,几乎不可能。Unicode很快意识到这个问题,并马上推出了兼容ASCII的方案:UTF-8,UTF-8也是目前使用最广泛的编码。
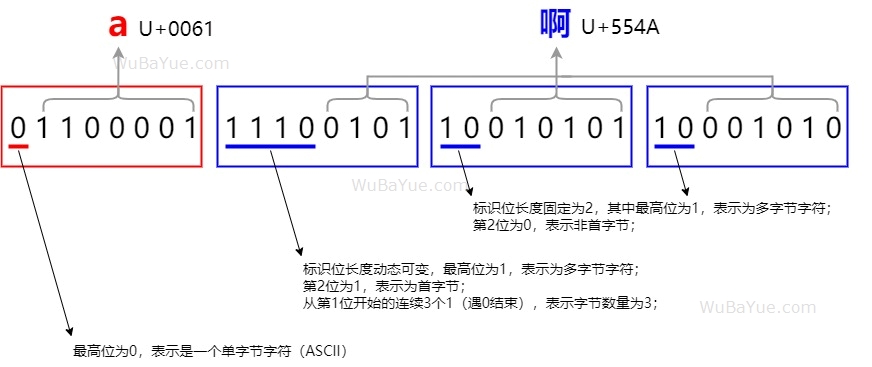
UTF-8是一个变长编码方案,允许使用1-4个字节来存放一个Unicode字符,编码逻辑如下: 首先判断第一个字节的最高位,如果为0,表示这是一个单字节ASCII字符(此处不得不佩服ASCII编码当初保留了最高位这个神英明神武的决定,否则后续的所有多字节编码方案都难以兼容ASCII了)。 如果最高位为1,表示这是一个多字节Unicode字符,从第1位开始连续有n个1(遇0结束)代表着这个字符连续占用了n个字节,然后后续的这n个字节中,前两位固定为标识符,后6位存放数据。
为便于理解,如上表格展示了UTF-8编码中1个字节到4个字节字符的编码示例,其中x表示数据位。因为UTF-8是目前使用最广泛的编码,基于兼容性考虑,在可预计的将来UTF-8也将具有长期统治地位,所以对于UTF-16与UTF-32本文就不作展开了。 转自https://www.cnblogs.com/wubayue/p/18907899 该文章在 2025/6/5 15:36:40 编辑过 |
关键字查询
相关文章
正在查询... 



|


 400 186 1886
400 186 1886